DevOps is an IT related concept heavily debated, marketed, talked-about in the industry for quite some years. What I love most about it is that it continuously improves; it is like a living organism, as any IT company built on people’s creativity, passion and knowledge.
As I see it, if DevOps would be a person, automation would be its heart, communication and knowledge sharing would be its blood, agile product management would be its brain while servant leadership (or even further — transformational leadership) would be its breathing air.
In this article I am going to have a look at the DevOps heart and how could we keep it pumping.
In a DevOps environment, practices such as continuous integration, continuous delivery, continuous deployment, continuous monitoring, continuous testing, self-healing, auto-scaling are a must; and all these can only be achieved by automating workflows, operations, whatever repetitive task that implies human effort.
In order to cover this automation need, several job titles appeared in the market: Build Engineer, Release Engineer, DevOps Engineer, Site Reliability Engineer, [Cloud] Platform Engineer and some other flavors of these ones. Of course, passionate debates and quite very well documented papers appeared on what exactly does it mean one or the other, how do they overlap, how do they complement and in which kind of organizational structure do they fit (if curious about it, please see the references of this article).
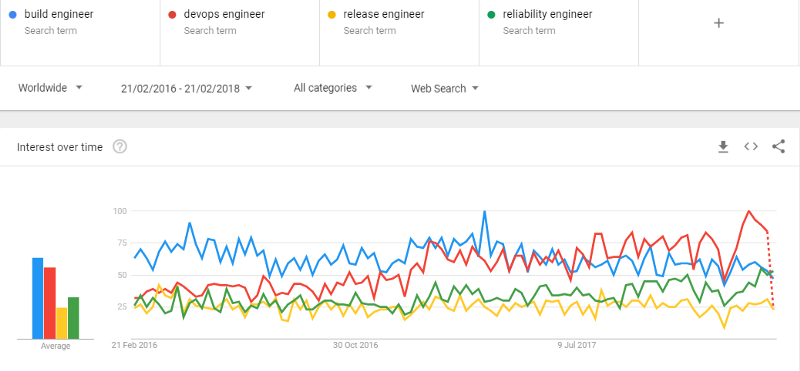
The understanding and the usage of these job titles depend also on the geographical location, in direct correlation with how many companies/teams have adopted DevOps (culture, methodology, processes, and tools). As reference, in the 2017 State of DevOps Report done by Puppet & DORA, it is stated that 54% of the software teams have adopted already DevOps in North America, 27% in Europe and Russia and 10% in Asia, so I expect some differences in the maturity level, thus in the job-related titles (implicitly, in roles & responsibilities).
From my observations on the Romanian jobs market, I have built the following picture with regards to these job titles topology:
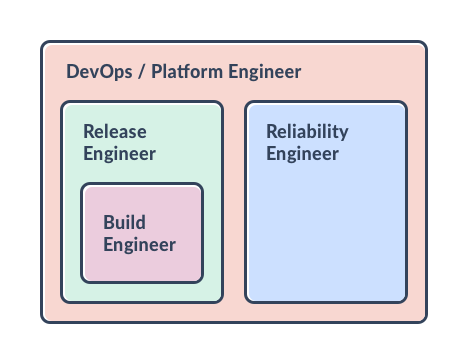
As a storyline, I would put it like this:
· two ~ three years ago, when I first made an analysis of the market, there were many job requests for Build Engineers, meaning someone with technical expertise in automating the build process, who would be able to implement continuous code integration, as a first step towards building a Continuous Delivery Pipeline (CDP). Specific technical skills that are mostly required for this role: source control management and tools (e.g GIT, SVN), scripting languages for packing the source code (e.g Ant, Maven, Makefile), CDP related tools (e.g Jenkins, Groovy, TeamCity, Artifactory, Nexus); knowledge on CDP workflow and technical components;
· then, for quite a small period of time, I have observed an increase of requests for so-called Release Engineers, from whom the companies demanded the same knowledge as for Build Engineers and, in addition, strong knowledge also on managing environments/platforms, configuration management & deployment automation, agile-specific tooling configuration/ administration/management. They were expected to build a complete, reliable Continuous Delivery Pipeline, connecting all the technical pieces together (e.g. integrating Selenium for test automation, Docker or Cloud Providers SDKs), implementing best practices in the workflow. The term is not that used anymore, at least on the Romanian market. Searching through LinkedIn Jobs, I can observe that also worldwide is not heavily used, in comparison with Build Engineer (a few times more job requests) or DevOps Engineer (which is requested like 10~15 times more). Maybe the word “release” was not that inspiring and everyone in the industry was thinking about the old release policies with long feedback loops and that is why it was more or less dropped off. On the other hand, Google mentions Release Engineer role in “Site Reliability Engineering. How Google runs production systems” book as defining “best practices for using [their] tools in order to make sure projects are released using consistent and repeatable methodologies. Examples include compiler flags, formats for build identification tags, and required steps during a build.”
· There is also an increasing number of requests for [Site] Reliability Engineers (SRE). This is a role launched by Google, heavily sustained by one of the top DevOps researchers, Jez Humble, which is rapidly gaining adoption, in a direct correlation also with Google Cloud Platform increase in the market share. SRE, as Google defines it, is a team with both coding and system engineering skills, which “is fundamentally doing work that has historically been done by an operations team, but using engineers with software expertise”. The team is expected to be responsible for the availability, latency, performance, efficiency, change management, continuous monitoring, emergency response, building up strategies for rollbacks, auto-scaling or self-healing. The required technical expertise is referring to performance monitoring tools (e.g DataDog, OMD, Grafana), Linux scripting, programming languages (e.g Go, Python, Java, JavaScript), cloud technologies (e.g Google Cloud Platform, AWS, OpenStack), microservices architecture.
Read the complete article here.
Written by Aura Virgolici, METRO SYSTEMS Romania